Machine Learning Algorithms: A Comprehensive Overview
Machine learning (ML) is a subset of artificial intelligence (AI) focused on developing systems that can learn from and make predictions or decisions based on data. At the core of this technology are machine learning algorithms, which are essentially mathematical models designed to identify patterns, make predictions, and improve their performance over time. This article delves into the various types of machine learning algorithms, their applications, and their significance in the modern technological landscape.
Understanding Machine Learning Algorithms
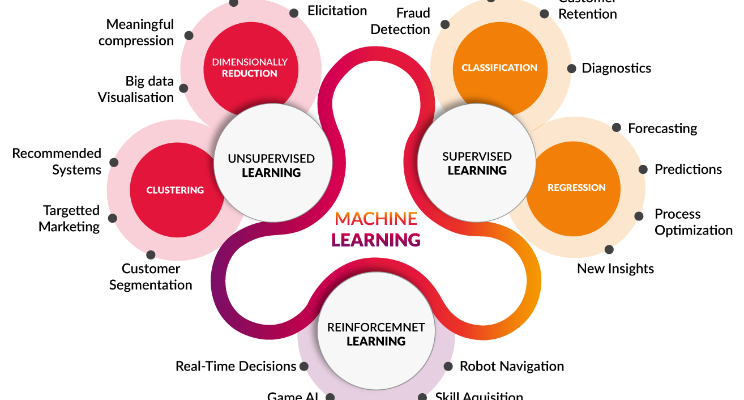
Machine learning algorithms can be broadly categorized into three types: supervised learning, unsupervised learning, and reinforcement learning. Each category serves different purposes and employs unique techniques for processing data.
1. Supervised Learning
Supervised learning algorithms are designed to learn from labeled data, meaning that each training example is paired with an output label. The goal is to learn a mapping from inputs to outputs, enabling the model to make predictions or classifications on new, unseen data.
a. Regression Algorithms
Regression algorithms are used when the output variable is continuous. The primary objective is to predict numerical values. Two common regression algorithms are:
Linear Regression: This is the simplest form of regression, where the relationship between the independent variable (X) and the dependent variable (Y) is assumed to be linear. The model tries to fit a straight line through the data points to minimize the difference between the predicted and actual values.
Polynomial Regression: An extension of linear regression, polynomial regression models the relationship between the independent and dependent variables as an nth-degree polynomial. This allows the model to fit more complex relationships in the data.
b. Classification Algorithms
Classification algorithms are used when the output variable is categorical. These algorithms assign input data into predefined classes or categories. Popular classification algorithms include:
Logistic Regression: Despite its name, logistic regression is used for binary classification problems. It models the probability that a given input belongs to a particular class using the logistic function, which outputs values between 0 and 1.
Support Vector Machines (SVM): SVM algorithms find the optimal hyperplane that separates different classes in the feature space. They are particularly effective in high-dimensional spaces and with datasets where the classes are not linearly separable.
Decision Trees: Decision trees split the data into subsets based on the value of input features. Each node in the tree represents a decision based on one of the features, and the branches represent the outcome of the decision. Decision trees are easy to interpret but can be prone to overfitting.
Random Forests: An ensemble method that combines multiple decision trees to improve the accuracy and robustness of predictions. Each tree in the forest is built on a random subset of the data, and the final prediction is made by aggregating the predictions from all trees.
2. Unsupervised Learning
Unsupervised learning algorithms work with unlabeled data. The goal is to identify patterns or structures within the data without predefined outcomes.
a. Clustering Algorithms
Clustering algorithms group data points into clusters based on their similarity. Common clustering algorithms include:
K-Means Clustering: K-means aims to partition the data into K clusters, where each cluster is represented by the mean of its data points. The algorithm iteratively assigns data points to the nearest cluster center and updates the cluster centers based on the new assignments.
Hierarchical Clustering: This method builds a hierarchy of clusters by either iteratively merging smaller clusters (agglomerative) or splitting larger clusters (divisive). The result is often presented as a dendrogram, a tree-like diagram that shows the arrangement of clusters.
b. Dimensionality Reduction Algorithms
Dimensionality reduction algorithms reduce the number of features or dimensions in the data while retaining essential information. Examples include:
Principal Component Analysis (PCA): PCA transforms the data into a new coordinate system where the greatest variances by any projection of the data come to lie on the first few coordinates, known as principal components. This helps in visualizing and reducing the complexity of the data.
t-Distributed Stochastic Neighbor Embedding (t-SNE): t-SNE is a technique for visualizing high-dimensional data by mapping it to a lower-dimensional space. It preserves local similarities and is particularly useful for exploring complex datasets.
3. Reinforcement Learning
Reinforcement learning (RL) algorithms focus on training agents to make decisions by rewarding desired behaviors and penalizing undesirable ones. The agent learns to take actions that maximize cumulative rewards over time.
a. Q-Learning
Q-Learning is a model-free RL algorithm that learns the value of taking a particular action in a given state. It uses a Q-table to store the expected rewards for action-state pairs and updates these values based on the observed rewards and the estimated future rewards.
b. Deep Q-Networks (DQN)
Deep Q-Networks combine Q-Learning with deep learning. Instead of using a Q-table, DQNs employ neural networks to approximate the Q-values. This allows RL to be applied to more complex environments with large state and action spaces.
c. Policy Gradient Methods
Policy gradient methods directly learn a policy that maps states to actions, rather than learning value functions. They optimize the policy parameters to maximize the expected reward. These methods are particularly useful in environments with continuous action spaces.
Applications of Machine Learning Algorithms
Machine learning algorithms are applied across a wide range of domains, revolutionizing various industries:
Healthcare: ML algorithms assist in diagnosing diseases, predicting patient outcomes, and personalizing treatment plans. For example, algorithms can analyze medical images to detect abnormalities or predict the likelihood of a patient developing a particular condition.
Finance: In finance, ML algorithms are used for fraud detection, algorithmic trading, and credit scoring. They can analyze transaction patterns to identify potentially fraudulent activities or predict stock market trends.
Marketing: ML algorithms help in customer segmentation, personalized recommendations, and targeted advertising. By analyzing customer data, companies can tailor their marketing strategies to individual preferences and behaviors.
Manufacturing: Predictive maintenance, quality control, and supply chain optimization are key applications of ML in manufacturing. Algorithms can predict equipment failures before they occur, ensuring smoother operations and reduced downtime.
Transportation: Autonomous vehicles, route optimization, and traffic management are some areas where ML is making an impact. Algorithms help self-driving cars navigate safely, optimize delivery routes, and manage traffic flow efficiently.
Challenges and Future Directions
While machine learning algorithms offer numerous benefits, they also face challenges:
Data Quality and Quantity: ML algorithms require large amounts of high-quality data to perform well. Ensuring data accuracy and addressing issues like missing or biased data are critical for effective model performance.
Interpretability: Some ML models, particularly complex ones like deep neural networks, are often seen as “black boxes,” making it difficult to understand how they arrive at their decisions. Improving the interpretability of these models is an ongoing area of research.
Ethical Considerations: The use of ML algorithms raises ethical concerns related to privacy, fairness, and accountability. Ensuring that algorithms are used responsibly and do not perpetuate biases is essential for their ethical deployment.
Looking ahead, advancements in ML algorithms are expected to focus on improving efficiency, robustness, and interpretability. Emerging areas like federated learning, which enables collaborative training of models without sharing raw data, and explainable AI, which aims to make models more transparent, are likely to play a significant role in shaping the future of machine learning.
Conclusion
Machine learning algorithms are the backbone of modern AI, enabling systems to learn from data, make predictions, and drive innovations across various fields. Understanding the different types of algorithms—supervised, unsupervised, and reinforcement learning—along with their applications and challenges, provides a foundation for leveraging ML to solve complex problems and unlock new opportunities. As the field continues to evolve, ongoing research and development will enhance the capabilities and impact of machine learning technologies, paving the way for a more intelligent and data-driven future.